728x90
반응형
ChatGPT를 이용하여 코딩 공부를 해보려 한다.
100일 동안 공부하고 기록할 것이다.
많이 읽어주시고 항상 감사하다. (훈수는 항상 환영한다.)
오랜만이다. 현실 생활이 너무 바빠 며칠간 못했다. 그래도 금방 돌아왔으니 열심히 다시 해보겠다. 목표는 100일 도전을 올해 5월 내에 끝내는 것이다. 응원해 주고 훈수해 주길 바란다.
내일, 모레에는 복습이 기다리고 있으니 오늘은 복습은 하지 않겠다.
Day 12: 프로젝트: 간단한 텍스트 분석기
- 텍스트 파일을 읽어 단어의 빈도를 계산하는 프로그램 작성.
1. 프로젝트 개요
목표
- 텍스트 파일을 읽기.
- 텍스트를 단어 단위로 나누기.
- 각 단어가 몇 번 나왔는지 계산.
- 결과를 빈도순으로 정렬해 출력.

먼저 위와 같은 txt파일을 만든다.

110은 왜 출력되는지는 모르겠다.

이렇게 프로그램을 만든 후

이렇게 출력시키면 된다.
선생님이 간단하게 설명해주셨다.
읽어보고 가자.
코드 설명
- 파일 읽기:지정된 파일을 읽어 텍스트 내용을 가져옵니다.
- 코드
with open(filename, "r") as file: text = file.read()
- 소문자로 변환 및 구두점 제거:
- text.lower(): 모든 문자를 소문자로 변환해 대소문자 차이를 없앱니다.
- string.punctuation: 파이썬의 내장 문자열 모듈로, 구두점 문자 목록을 제공합니다.
- text.replace(punct, ""): 각 구두점을 빈 문자열로 대체합니다.
- 단어 분리:공백을 기준으로 텍스트를 단어 리스트로 분리합니다.
-
코드words = text.split()
- 단어 빈도 계산:
- 단어가 이미 사전에 있으면 기존 값에 1을 더합니다.
- 단어가 없으면 기본값 0을 사용하고 1을 더합니다.
-
코드word_count[word] = word_count.get(word, 0) + 1
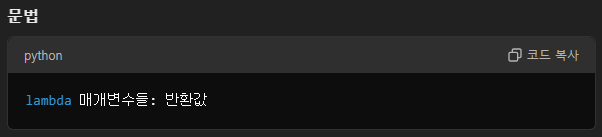
- 정렬:sorted() 함수와 lambda를 사용해 빈도수를 기준으로 내림차순 정렬합니다.
-
코드sorted_word_count = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
- 출력: 정렬된 단어와 빈도를 반복문을 통해 출력합니다.
추가로 두 가지만 더 해보자.
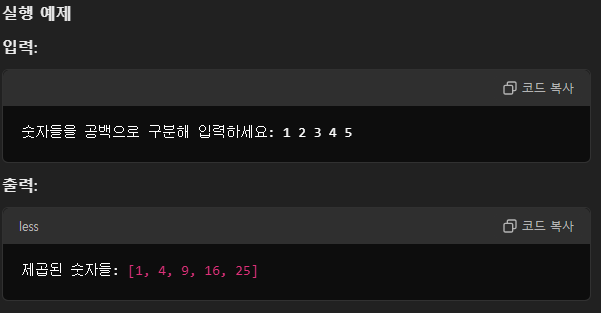
1. 상위 N개의 단어만 출력하기
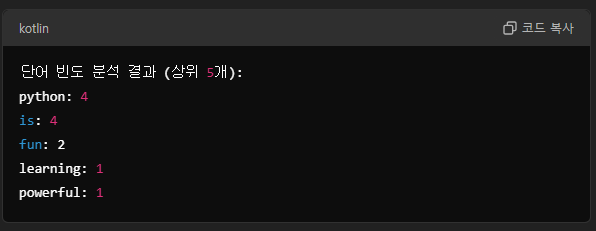
5개를 해보자

이렇게 프로그램을 만들었다.

띄어쓰기를 잘못했더니 결과가 좀 다르다.
그래도 괜찮다. ㅋㅋ
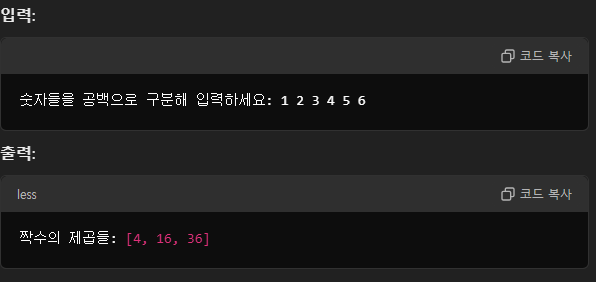
2. 단어 길이별 빈도 분석
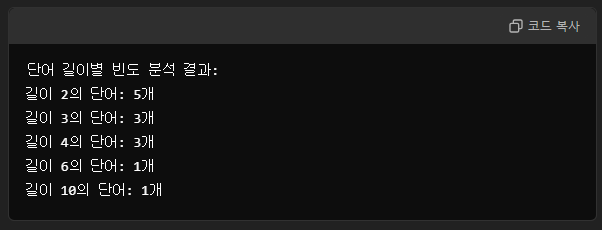
아마 이것도 조금 다를 것 같지만 바로 도전해보겠다.

이렇게 만들고
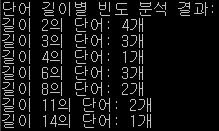
결과는 이렇게 나왔다.
어쩔 수 없지 ㅋㅋㅋㅋ
오늘은 이만
읽어주셔서 감사하다.
반응형
'코딩 100일 도전' 카테고리의 다른 글
| 취미로 코딩 공부하기 14일차 (1) | 2025.01.18 |
|---|---|
| 취미로 코딩 공부하기 13일차 (0) | 2025.01.17 |
| 취미로 코딩 공부하기 11일차 (0) | 2025.01.07 |
| 취미로 코딩 공부하기 10일차 (0) | 2025.01.06 |
| 취미로 코딩 공부하기 9일차 (2) | 2025.01.05 |